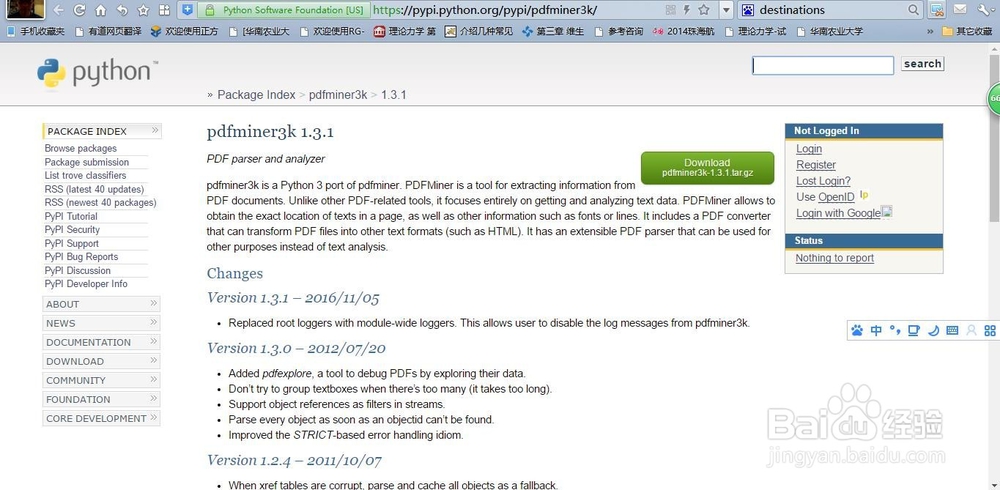
1、PDFParser:从一个文件中获取数据
PDFDocument:保存获取的数据,和PDFParser是相互关联的
PDFPageInterPReter处理页面内容
PDFDevice将其翻译成你需要的格式
PDFResourceManager用于存储共享资源,如字体或图像。
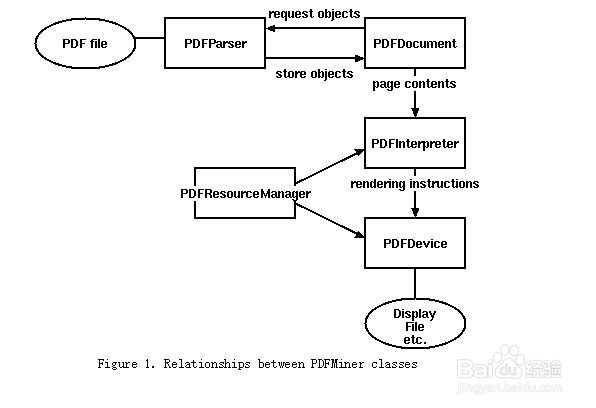
2、from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager,process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(pdffile):
rsrcmgr=PDFResourceManager()
retstr=StringIO()
laparams=LAParams()
device=TextConverter(rsrcmgr,retstr,laparams=laparams)
process_pdf(rsrcmgr,device,pdffile)
device.close()
content=retstr.getvalue()
retstr.close()
return content
pdffile=urlopen('http://pythonscraping.com/pages/warandpeace/chapter1.pdf')
outputString=readPDF(pdffile)
print(outputString)
pdffile.close()
读取一个pdf文档。
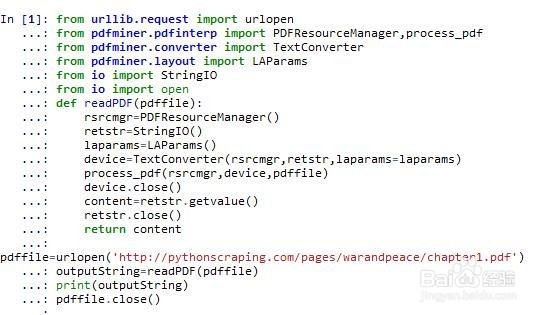

3、LTPage :表示整个页。可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象。
LTTextBox:表示一组文本块可能包含在一个矩形区域。注意此box是由几何分析中创建,并且不一定表示该文本的一个逻辑边界。它包含LTTextLine对象的列表。使用 get_text()方法返回的文本内容。
LTTextLine :包含表示单个文本行LTChar对象的列表。字符对齐要么水平或垂直,取决于文本的写入模式。get_text()方法返回的文本内容。
LTChar
LTAnno:在文本中实际的字母表示为Unicode字符串(?)。需要注意的是,虽然一个LTChar对象具有实际边界,LTAnno对象没有,因为这些是“虚拟”的字符,根据两个字符间的关系(例如,一个空格)由布局分析后插入。
LTImage:表示一个图像对象。嵌入式图像可以是JPEG或其它格式,但是目前PDFMiner没有放置太多精力在图形对象。
LTLine:代表一条直线。可用于分离文本或附图。
LTRect:表示矩形。可用于框架的另一图片或数字。
LTCurve:表示一个通用的Bezier曲线
4、from pdfminer.pdfparser import PDFParser, PDFDocument
file=open(path, 'rb')
parser=PDFParser(file)
document=PDFDocument()
parser.set_document(document)
document.set_parser(parser)
document.initialize(password)
outlines=document.get_outlines()
for (level,title,dest,a,se) in outlines:
print (level, title,dest,a,se)
输出pdf文件的等级,标题等参数


5、从官网下载软件,解压,并使用
win+R cmd回车
cd 文件路径
python setup.py install