1、首先我们打开编辑器,然后新建一个py后缀的文件,这是一个PYTHON的文件。

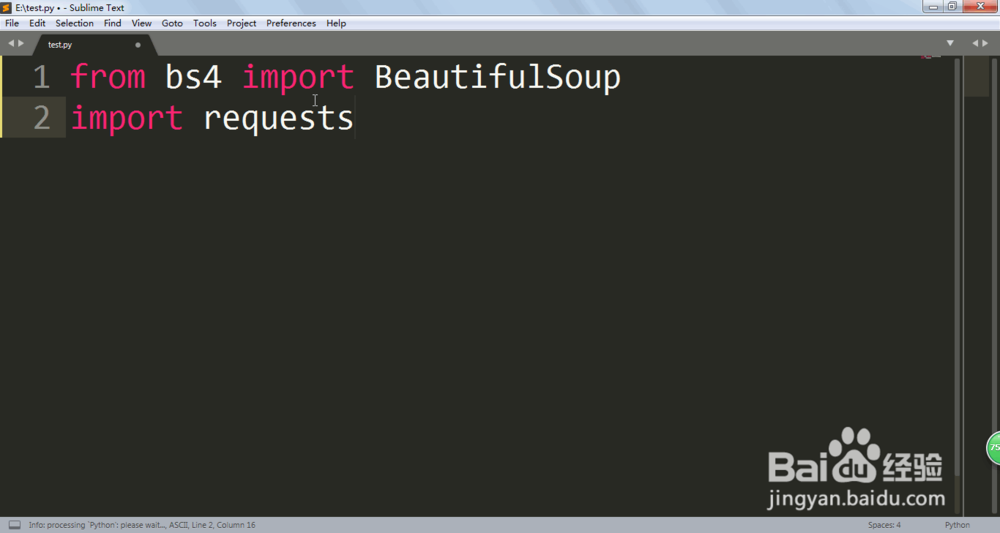
2、from bs4 import BeautifulSoup
import requests
首先要引入这两个库,这是要爬虫的非常常见的库,等会会展现他们的功能。
3、website = "网页"
result = requests.get(website)
result.encoding = "utf-8"
content = result.text
print(content)
这里我们就可以用requests这个库来先获取整个网页的HTML代码。并且打始没印一下查看是否有问题。

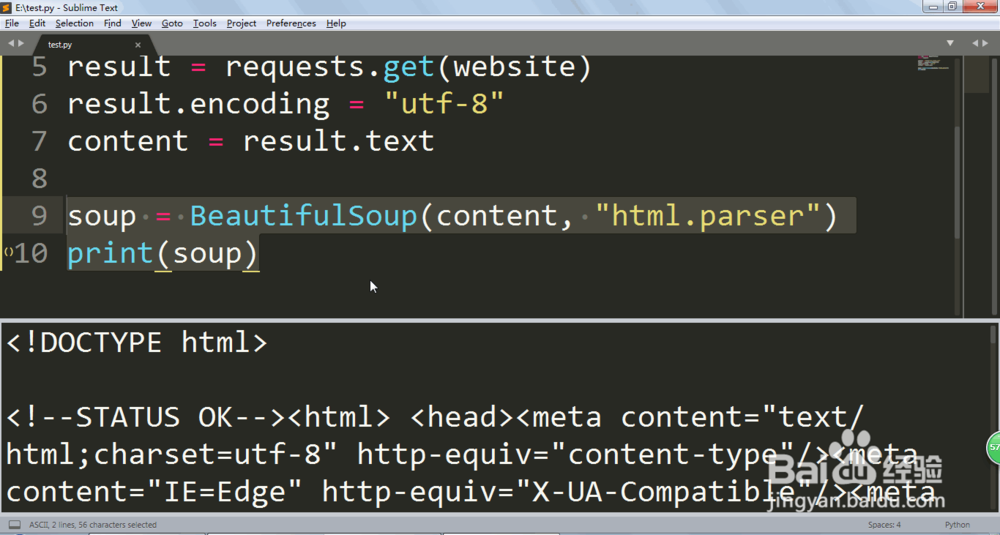
4、soup = BeautifulSoup(content, "html.parser")
print(soup)
接着就是用BeautifulSoup来解析一下内容,并且保存在变量里面。
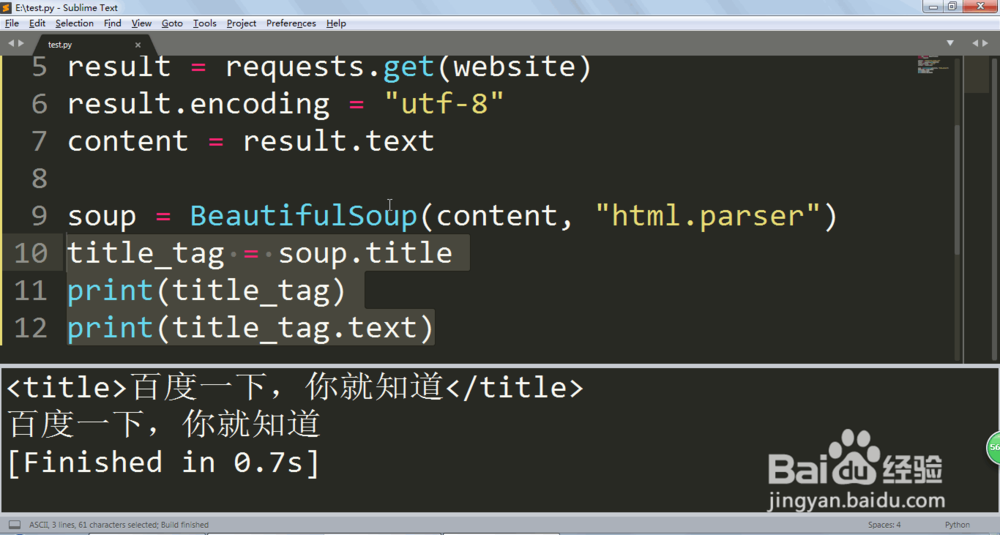
5、现在可以来判断和获取HTML标签了,HTML标签是由<></>央棍盯这样的格式撤酱组成的。
title_tag = soup.title
print(title_tag)
print(title_tag.text)
比如我们看到了title标签想获取,就可以指定名字即可,如果要里面的内容可以用text。
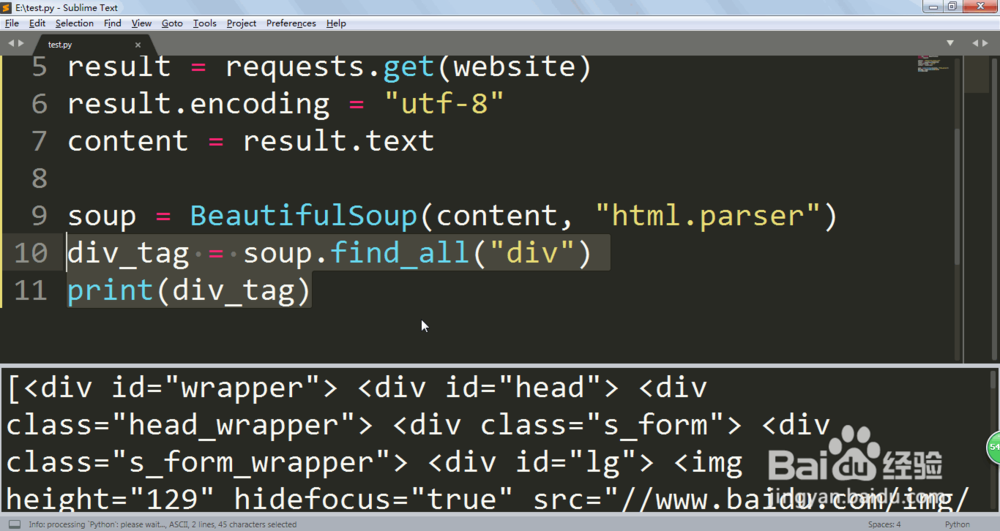
6、但是往往标签都是有多个的,我们需要用find_all()来把所有给找出来。
div_tag = soup.find_all("div")
print(div_tag)
然后PYTHON会存储在列表里面。