1、打开JUPYTER NOTEBOOK,新建一个空白的PY文档。
2、#http://
#https://
这是一般的格式,我们需要找到这样的格式字符。

3、import re
引入regular expression模块,然后才能运用相应的函数。

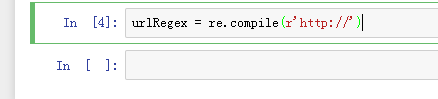
4、urlRegex = re.compile(r'http://')
首先要在前面加上r来表示raw string。
5、urlRegex = re.compile(r'[a-z]{4}://')
urlRegex.search(r'http://www.heyheyhey.com')
http可以用26个字母来代替,然后注明4个字母。

6、urlRegex = re.compile(r'''[a-z]{4}://''')
urlRegex.search(r'http://www.heyheyhey.com')
建议用三引号来选中比较好。

7、urlRegex = re.compile(r'''\w{4}://''')
urlRegex.search(r'http://www.heyheyhey.com')
\w也是可以表示字母的。

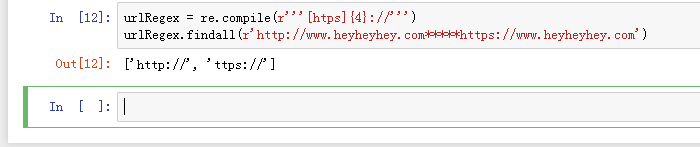
8、urlRegex = re.compile(r'''[htps]{4}://''')
urlRegex.findall(r'http://www.heyheyhey.com*****https://www.heyheyhey.com')
中括号则可以指定字母,两个t只需要写一个。
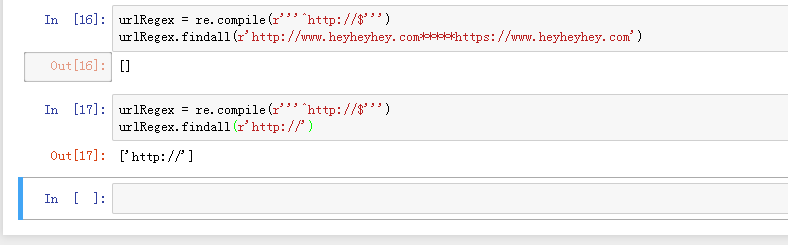
9、urlRegex = re.compile(r'''^http://$''')
urlRegex.findall(r'http://www.heyheyhey.com*****https://www.heyheyhey.com')
urlRegex = re.compile(r'''^http://$''')
urlRegex.findall(r'http://')
用^和$只能针对字符首尾,不太适用在这里。
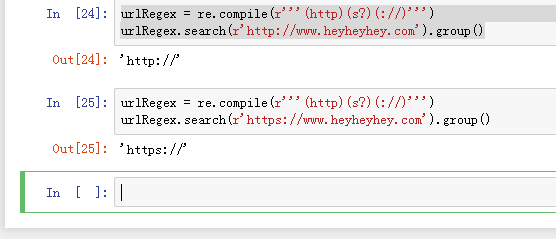
10、urlRegex = re.compile(r'''(http)(s?)(://)''')
urlRegex.search(r'http://www.heyheyhey.com').group()
urlRegex = re.compile(r'''(http)(s?)(://)''')
urlRegex.search(r'https://www.heyheyhey.com').group()
用问号表示零个或者多个。
11、urlRegex = re.compile(r'''http://|https://''')
urlRegex.search(r'http://www.heyheyhey.com').group()
urlRegex = re.compile(r'''http://|https://''')
urlRegex.search(r'https://www.heyheyhey.com').group()
用|字符表示或者。

